Wie visualisiert man viel Information, so dass sie auf einen Blick – zumindest grob – erfassbar und vergleichbar ist? Eine Möglichkeit für nicht-räumliche Daten besteht in einer sogenannten Scatterplot Matrix (oder auf Deutsch: Streudiagramm-Matrix):
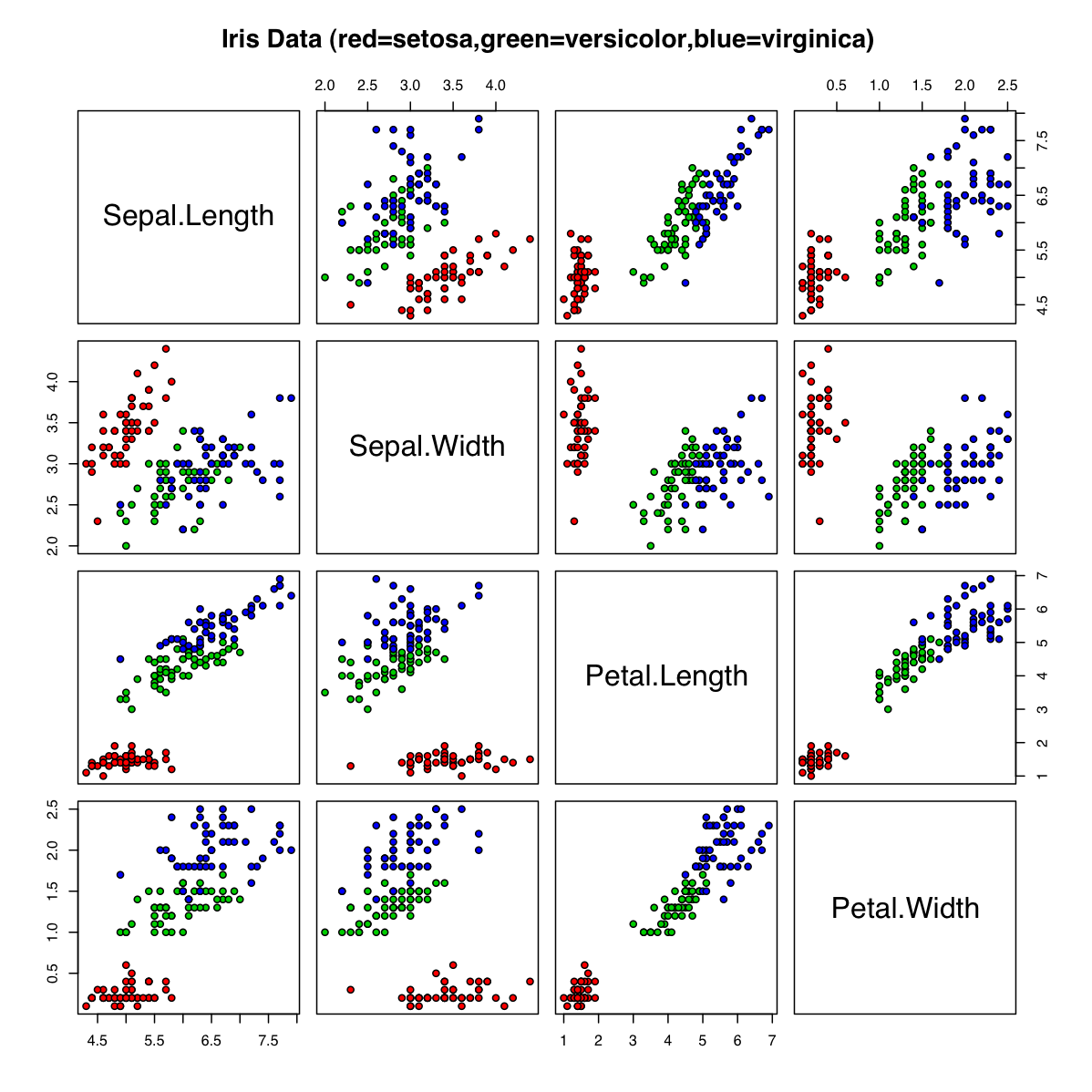
Eine Scatterplot Matrix zeigt ein Set von Scatterplots desselben mehrdimensionalen Datensatzes. Sie ist zum Beispiel einfach in der Software R umsetzbar, meines Wissen aber zum Beispiel in Excel nicht unterstützt. Die Attribute des visualisierten Datensatzes sind dabei in der Regel in der Diagonalen beschriftet. Manchmal enthält die Diagonale auch Histogramme bzw. Verteilungsfunktionen des jeweiligen Attributs. In einer Scatterplot Matrix kann man also alle visualisierten Attribute miteinander vergleichen und untersuchen, wie sie ko-variieren. Die Matrix bietet somit eine grosse Informationsfülle auf kleinem Raum.
Im Prinzip verkörpert eine Scatterplot Matrix das Konzept des small multiple, welches durch Edward Tufte Verbreitung gefunden hat. Ein Small Multiple ist (etwas vereinfacht und verallgemeinert gesagt) eine Ansammlung kleiner, sehr ähnlich gestalteter Darstellungen, welche unterschiedliche Sichten auf denselben Datensatz ermöglichen. Dieses Prinzip lässt sich auch sehr gut auf die Visualisierung räumlicher Informationen anwenden. Man kann so ähnlich zur Scatterplot Matrix verschiedene Attribute visualisieren oder aber auch das räumliche Muster von Kategorien darstellen.
Dieses zweite Vorhaben habe ich anhand des frei verfügbaren Baumkatasters der Stadt Zürich beispielhaft umgesetzt:
 Ich habe in diesem Beispiel in allen Einzeldarstellungen dieselben Kontextinformationen eingeblendet: Topographie mit einer Reliefschattierung (erlaubt die Abschätzung der Höhe, Neigung und Exposition), Fliessgewässer, stehende Gewässer sowie die Stadtgrenze von Zürich. In Rot ist schliesslich die Verbreitung von Baumgattungen dargestellt. Eine Gattung (Genus) umfasst verschiedene Pflanzenarten, „Acer“ als Genus umfasst also verschiedene Arten von Ahorn. Die deutschsprachige Bezeichnung meint also nicht eine spezifische Art, sondern steht stets für eine Gruppe von Baumarten.
Ich habe in diesem Beispiel in allen Einzeldarstellungen dieselben Kontextinformationen eingeblendet: Topographie mit einer Reliefschattierung (erlaubt die Abschätzung der Höhe, Neigung und Exposition), Fliessgewässer, stehende Gewässer sowie die Stadtgrenze von Zürich. In Rot ist schliesslich die Verbreitung von Baumgattungen dargestellt. Eine Gattung (Genus) umfasst verschiedene Pflanzenarten, „Acer“ als Genus umfasst also verschiedene Arten von Ahorn. Die deutschsprachige Bezeichnung meint also nicht eine spezifische Art, sondern steht stets für eine Gruppe von Baumarten.
Die Kontextinformationen in der obigen Darstellung erlauben es zumindest theoretisch, gewisse Interpretationen bezüglich der Verbreitungen anzustellen („Theoretisch“ weil die Verbreitung von Bäumen in der Stadt sich natürlich auch im besten Fall nur teilweise anhand ökologischer Faktoren erklären lässt. Ebenso wichtig sind wohl Pflanz-Zeitpunkt, Modeströmungen beim Stadtgrün, sprich: die Gestaltungsfreiheit von Grün Stadt Zürich 🙂 ).
Die small multiple-Darstellung funktioniert meiner Meinung nach auch bei räumlichen Daten sehr gut. Ich verwende sie gerne, um multikategoriale Daten zu visualisieren. Stellen sie sich vor, alle Baumgattungen wären in einer Karte dargestellt, bespielsweise als verschiedenfarbige, sich deutlich überlappende Punkte! Oder etwas fortgeschrittener: die Darstellung wäre umgesetzt als ein Set bivariater oder multivariater Choroplethen-Karten (man lese hierzu den vorzüglichen Beitrag von Joshau Stevens: http://www.joshuastevens.net/cartography/make-a-bivariate-choropleth-map). Beide Darstellungsarten wären bei einer stattlichen Anzahl von Baumgattungen unglaublich schwierig zu lesen.
Die small multiple-Darstellung löst die Aufgabe hingegen effektiv und effizient. Der Fokus liegt hier natürlich nicht auf der Detailgenauigkeit sondern auf dem „big picture“ und dem einfachen Vergleich.
Da mich die Datenfülle des Baumkatasters so begeistert hat, habe ich noch eine etwas künstlerischere Variante umgesetzt:
 Interessanterweise funktioniert der Vergleich zwischen Verbreitungsmustern von Baumgattungen in dieser im Informationsgehalt sehr reduzierten Form besser, da wir uns wegen des Wegfalls der Kontextinformationen vollends auf diese Muster konzentrieren können.
Interessanterweise funktioniert der Vergleich zwischen Verbreitungsmustern von Baumgattungen in dieser im Informationsgehalt sehr reduzierten Form besser, da wir uns wegen des Wegfalls der Kontextinformationen vollends auf diese Muster konzentrieren können.
Wenn Sie die Darstellung mögen: Ein Klick auf obiges Bild liefert eine hochaufgelöste Rastergrafik (PNG-Datei), mit einem Klick hier können Sie eine PDF-Datei in guter Qualität herunterladen (Format A1).
{kind=link}